L'ETL open source
Ogni applicazione di Business Intelligence deve fondarsi su solide basi per produrre i risultati attesi. E' quindi importante che si appoggi su di un data warehouse ben progettato, ma anche correttamente caricato; infatti un'applicazione di BI non può prescindere dalla correttezza e certificazione dei dati che da essa vengono pubblicati. Esistono da anni strumenti che aiutano ad ottenere questi obiettivi, essi vengono chiamati strumenti ETL (Extract, Trasform and Loading). Tipicamente sono strumenti specializzati e molto o abbastanza costosi (IBM - Datastage, Oracle - ODI, ...), in alcuni casi sono forniti con il tool di analisi e reporting (Business Object - Data Integrator), oppure fanno parte del DBMS (Microsoft SQL Server - DTS). Esiste anche una proposta open source, si tratta di Pentaho Data Integration (ex Kettle), un tool che fa parte della ricca proposta Pentaho nel campo della BI. Che cos’è Pentaho Data Integration Fornire una singola versione della verità, consistente, attraverso tutte le fonti informative dell’azienda è una delle più grandi sfide di una organizzazione IT al giorno d’oggi. Pentaho Data Integration (PDI) dispone di potenti capacità di estrazione, trasformazione e caricamento (ETL - Extraction, Transformation and Loading), è composto da un insieme di strumenti che permettono di trasferire e manipolare i dati tra varie fonti, tipicamente DBMS e files nei vari formati. PDI utilizza un approccio innovativo basato sulla definizione di metadati per la descrizione ed il salvataggio dei processi di ETL, è indipendente dalla piattaforma ed ha un’architettura basata su standard internazionali. Dispone inoltre di un’interfaccia grafica di progetto molto intuitiva, di tipo “drag-and-drop”, a vantaggio della produttività. PDI è strumento ETL completo, supporta trasformazioni complesse, dispone di: PDI è uno strumento di 4° generazione, frutto di una ormai lunga evoluzione del software design: A cosa serve PDI PDI, come abbiamo detto, è uno strumento ETL progettato per: Sebbene molti di questi concetti possono essere applicati a quasi tutte le attività di import / export di dati, l’ETL è più frequentemente utilizzato in un ambiente di data warehouse. L’architettura di PDI PDI è realizzato su un’architettura aperta, basata su standards. I maggiori benefici architetturali includono: Un approccio basato su metadati significa che l’utente deve specificare CHE COSA vuole e non COME vuole fare. Nessun bisogno di realizzare codice personalizzato. Nessuna attività di programmazione, è un compito puramente dichiarativo. I modelli possono essere salvati all’interno di un database relazionale o sotto forma di file XML. I vantaggi derivanti dall’uso di un repository sono molteplici: possibilità di gestire più modelli, i modelli sono salvati in un formato strutturato, il repository può essere interrogato liberamente, è possibile mantenere all’interno del repository i log delle singole operazioni effettuate. I componenti di PDI PDI è costituito da quattro distinte applicazioni: SPOON Strumento che consente di modellare, ad alto livello, il flusso dei dati dalla sorgente, attraverso le trasformazioni, fino alla destinazione utilizzando un’interfaccia grafica. PAN Strumento a linea di comando che consente di interpretare ed eseguire direttamente, in modalità batch, i modelli e le trasformazioni disegnate con Spoon, per esempio mediante uno scheduler. CHEF Consente di creare graficamente dei jobs. Un job consiste in una serie di operazioni come trasformazioni, FTP, downloads, etc. poste all’interno di un flusso di controllo. Un job automatizza ulteriormente il completamento di operazioni (task) di aggiornamento di un data warehouse permettendo il controllo sulla corretta esecuzione di ogni script, trasformazione o job. KITCHEN Si tratta di uno strumento a linea di comando utilizzato per lanciare l’esecuzione dei jobs disegnati con Chef in modalità batch. PDI è OPEN SOURCE PDI, dalla versone 2.2 è gratuito. I sorgenti completi sono rilasciati sotto la Lesser GNU Public License. Pentaho Data Integration non ha costi di licenza e consente una significante riduzione del TCO in confronto con soluzioni custom. A fronte di un abbonamento annuale viene inoltre fornito un supporto professionale e release certificate. http://www.pentaho.com/products/data_integration/
Pubblico di seguito un documento che sintetizza gli aspetti principali dello strumento. Il documento è una sintesi realizzata da Beta 80 Group.
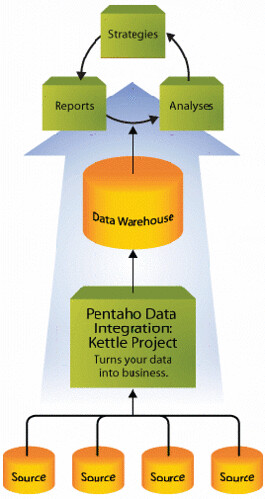
Caratteristiche peculiari di PDI sono un approccio metadata-driven (basato sulla definizione di uno livello di metadati), model-driven (fondato sull’utilizzo di modelli) e repository-based (basato sull’utilizzo di un repository). 
 Fig. 1: Semplice flusso
Fig. 1: Semplice flusso
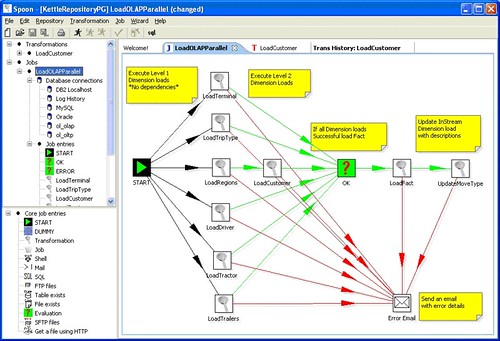 Fig. 4: Flusso complesso con alert via email
Fig. 4: Flusso complesso con alert via email
Links


Nessun commento:
Posta un commento